Recurring Anomaly Detection System (ReADS)
An algorithm shared by DAWN MCINTOSH, updated on Sep 10, 2010
Summary
Overview:
ReADS can analyze text reports, such as aviation reports and problem or maintenance records. ReADS uses text clustering algorithms to group loosely related reports and documents, this reduces human error and fatigue. Plus, ReADS identifies interconnected reports; automating the discovery of possible recurring anomalies. ReADS provides a visualization of the clusters and recurring anomalies. ReADS has been integrated into a secure web-based search tool to allow uses to perform their own text mining.
Recurring Anomaly Identification
ReADS identifies reports which mention other reports as a recurring anomaly using regular expressions to search documents and identify references of other reports by name. ReADS also detects recurring anomalies by determining the similarity between documents using a cosine distance similarity measure. Then according to the similarity measure, ReADS will run a hierarchical clustering algorithm to detect the recurring anomalies. The hierarchical tree is partitioned into clusters by setting a threshold. A low threshold implies that the reports must be very similar to be sorted into the same cluster.
Here's more info.
The figure below is a screenshot of the clustering results.
Source Files
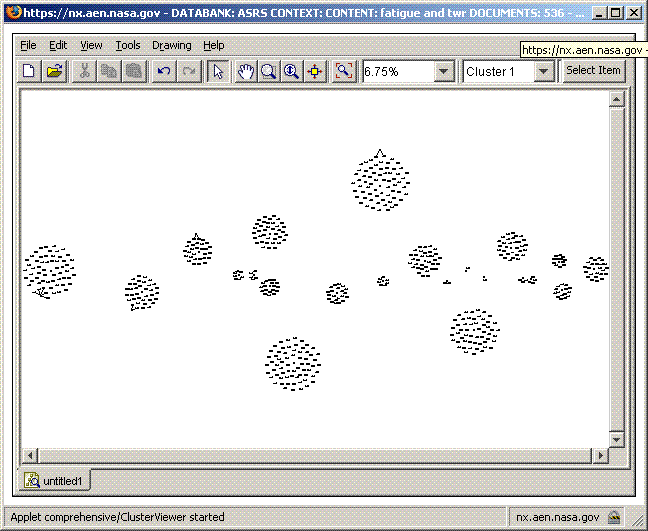 ReADS_clusteringVisualization.gif
ReADS_clusteringVisualization.gif
Support/Documentation (edit)
For any questions, contact this resource's administrator: NDC-dmcintos
Discussions
DAWN's Projects (2)
-
 Text Mining - Classification ...
Text Mining - Classification ...2 members
-
 ADAPT - An Electrical ...
ADAPT - An Electrical ...7 members
Need help?
Visit our help center